Massive designs, such as T5, GPT-3, PaLM, Flamingo and PaLI, have actually shown the capability to save significant quantities of understanding when scaled to 10s of billions of specifications and trained on big text and image datasets. These designs attain cutting edge outcomes on downstream jobs, such as image captioning, visual concern answering and open vocabulary acknowledgment. Regardless of such accomplishments, these designs need an enormous volume of information for training and wind up with a significant variety of specifications (billions in most cases), leading to considerable computational requirements. Furthermore, the information utilized to train these designs can end up being out-of-date, needing re-training each time the world’s understanding is upgraded. For instance, a design trained simply 2 years ago may yield out-of-date info about the existing president of the United States.
In the fields of natural language processing ( RETRO, WORLD) and computer system vision ( KAT), scientists have actually tried to attend to these difficulties utilizing retrieval-augmented designs. Usually, these designs utilize a foundation that has the ability to process a single method at a time, e.g., just text or just images, to encode and recover info from an understanding corpus. Nevertheless, these retrieval-augmented designs are not able to take advantage of all offered techniques in a question and understanding corpora, and might not discover the info that is most valuable for producing the design’s output.
To attend to these concerns, in “ REVEAL: Retrieval-Augmented Visual-Language Pre-Training with Multi-Source Multimodal Understanding Memory“, to appear at CVPR 2023, we present a visual-language design that discovers to make use of a multi-source multi-modal “memory” to address knowledge-intensive inquiries. Expose utilizes neural representation knowing to encode and transform varied understanding sources into a memory structure including key-value sets. The secrets work as indices for the memory products, while the matching worths save essential info about those products. Throughout training, REVEAL discovers the essential embeddings, worth tokens, and the capability to recover info from this memory to attend to knowledge-intensive inquiries. This method enables the design specifications to concentrate on thinking about the question, instead of being committed to memorization.
 |
| We enhance a visual-language design with the capability to recover several understanding entries from a varied set of understanding sources, which assists generation. |
Memory building from multimodal understanding corpora
Our method resembles WORLD because we precompute essential and worth embeddings of understanding products from various sources and index them in a merged understanding memory, where each understanding product is encoded into a key-value set. Each secret is a d– dimensional embedding vector, while each worth is a series of token embeddings representing the understanding product in more information. In contrast to previous work, REVEAL leverages a varied set of multimodal understanding corpora, consisting of the WikiData understanding chart, Wikipedia passages and images, web image-text sets and visual concern answering information Each understanding product might be text, an image, a mix of both (e.g., pages in Wikipedia) or a relationship or quality from a understanding chart (e.g., Barack Obama is 6′ 2″ high). Throughout training, we continually re-compute the memory secret and worth embeddings as the design specifications get upgraded. We upgrade the memory asynchronously at every thousand training actions.
Scaling memory utilizing compression
A naïve service for encoding a memory worth is to keep the entire series of tokens for each understanding product. Then, the design might fuse the input question and the top-k obtained memory worths by concatenating all their tokens together and feeding them into a transformer encoder-decoder pipeline. This method has 2 concerns: (1) keeping numerous countless understanding products in memory is not practical if each memory worth includes numerous tokens and (2) the transformer encoder has a quadratic intricacy with regard to the overall variety of tokens times k for self-attention For that reason, we propose to utilize the Beholder architecture to encode and compress understanding products. The Beholder design utilizes a transformer decoder to compress the complete token series into an approximate length. This lets us recover leading- k memory entries for k as big as a hundred.
The following figure shows the treatment of building the memory key-value sets. Each understanding product is processed through a multi-modal visual-language encoder, leading to a series of image and text tokens. The essential head then changes these tokens into a compact embedding vector. The worth head (beholder) condenses these tokens into less ones, keeping the essential info about the understanding product within them.
 |
| We encode the understanding entries from various corpora into merged secret and worth embedding sets, where the secrets are utilized to index the memory and worths consist of info about the entries. |
Massive pre-training on image-text sets
To train the REVEAL design, we start with the massive corpus, gathered from the general public Web with 3 billion image alt-text caption sets, presented in LiT Because the dataset is loud, we include a filter to eliminate information points with captions much shorter than 50 characters, which yields approximately 1.3 billion image caption sets. We then take these sets, integrated with the text generation unbiased utilized in SimVLM, to train REVEAL. Provided an image-text example, we arbitrarily sample a prefix including the very first couple of tokens of the text. We feed the text prefix and image to the design as input with the goal of producing the remainder of the text as output. The training objective is to condition the prefix and autoregressively create the staying text series.
To train all elements of the REVEAL design end-to-end, we require to warm start the design to an excellent state (setting preliminary worths to design specifications). Otherwise, if we were to begin with random weights (cold-start), the retriever would frequently return unimportant memory products that would never ever create beneficial training signals. To prevent this cold-start issue, we build a preliminary retrieval dataset with pseudo– ground-truth understanding to provide the pre-training a sensible running start.
We develop a customized variation of the WIT dataset for this function. Each image-caption set in WIT likewise features a matching Wikipedia passage (words surrounding the text). We assembled the surrounding passage with the question image and utilize it as the pseudo ground-truth understanding that represents the input question. The passage offers abundant info about the image and caption, which works for initializing the design.
To avoid the design from depending on low-level image functions for retrieval, we use random information enhancement to the input question image. Provided this customized dataset which contains pseudo-retrieval ground-truth, we train the question and memory essential embeddings to warm start the design.
REVEAL workflow
The total workflow of REVEAL includes 4 main actions. Initially, REVEAL encodes a multimodal input into a series of token embeddings together with a condensed question embedding. Then, the design equates each multi-source understanding entry into merged sets of essential and worth embeddings, with the secret being made use of for memory indexing and the worth incorporating the whole info about the entry. Next, REVEAL recovers the top- k most associated understanding pieces from several understanding sources, returns the pre-processed worth embeddings kept in memory, and re-encodes the worths. Lastly, REVEAL merges the top- k understanding pieces through a mindful understanding blend layer by injecting the retrieval rating (dot item in between question and essential embeddings) as a prior throughout attention estimation. This structure contributes in allowing the memory, encoder, retriever and the generator to be simultaneously trained in an end-to-end style.
 |
| Total workflow of REVEAL. |
Outcomes
We assess REVEAL on knowledge-based visual concern answering jobs utilizing OK-VQA and A-OKVQA datasets. We tweak our pre-trained design on the VQA jobs utilizing the very same generative goal where the design takes in an image-question set as input and produces the text response as output. We show that REVEAL attains much better outcomes on the A-OKVQA dataset than earlier efforts that integrate a repaired understanding or the works that make use of big language designs (e.g., GPT-3) as an implicit source of understanding.
 |
| Visual concern answering results on A-OKVQA. Expose attains greater precision in contrast to previous works consisting of ViLBERT, LXMERT, ClipCap, KRISP and GPV-2 |
We likewise assess REVEAL on the image captioning standards utilizing MSCOCO and NoCaps dataset. We straight tweak REVEAL on the MSCOCO training split through the cross-entropy generative goal. We determine our efficiency on the MSCOCO test split and NoCaps examination set utilizing the CIDEr metric, which is based upon the concept that excellent captions must resemble reference captions in regards to word option, grammar, significance, and material. Our outcomes on MSCOCO caption and NoCaps datasets are revealed listed below.
 |
| Image Captioning results on MSCOCO and NoCaps utilizing the CIDEr metric. Expose attains a greater rating in contrast to Flamingo, VinVL, SimVLM and CoCa |
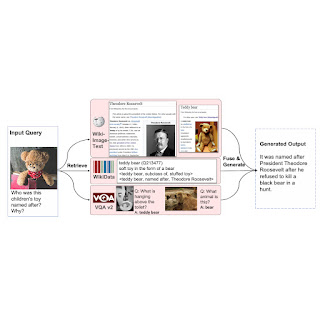
Listed below we reveal a number of qualitative examples of how REVEAL recovers pertinent files to address visual concerns.
 |
| REVEAL can utilize understanding from various sources to properly address the concern. |
Conclusion
We provide an end-to-end retrieval-augmented visual language (REVEAL) design, which includes an understanding retriever that discovers to make use of a varied set of understanding sources with various techniques. We train REVEAL on an enormous image-text corpus with 4 varied understanding corpora, and attain cutting edge outcomes on knowledge-intensive visual concern answering and image caption jobs. In the future we want to check out the capability of this design for attribution, and use it to a wider class of multimodal jobs.
Recognitions
This research study was performed by Ziniu Hu, Ahmet Iscen, Chen Sun, Zirui Wang, Kai-Wei Chang, Yizhou Sun, Cordelia Schmid, David A. Ross and Alireza Fathi.